Up to 12X faster GPU inference on Bert, T5 and other transformers with OpenAI Triton kernels
We are releasing Kernl under Apache 2 license, a library to make PyTorch models inference significantly faster. With 1 line of code we applied the optimizations and made Bert up to 12X faster than Hugging Face baseline. T5 is also covered in this first release (> 6X speed up generation and we are still halfway in the optimizations!). This has been possible because we wrote custom GPU kernels with the new OpenAI programming language Triton and leveraged TorchDynamo.
- Project link
- E2E demo notebooks: XNLI classification, T5 generation
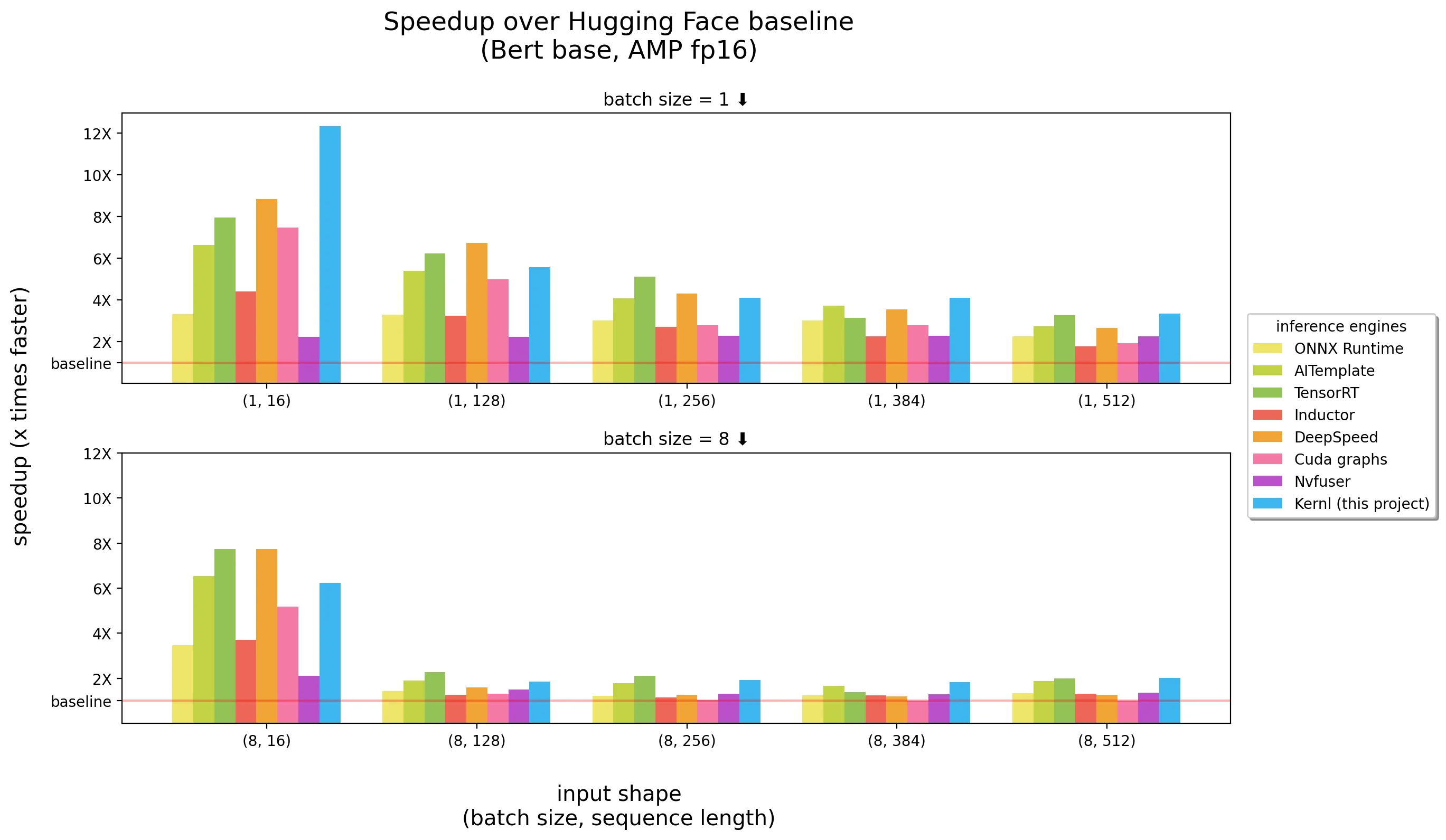
On long sequence length inputs, Kernl is most of the time the fastest inference engine, and close to Nvidia TensorRT on shortest ones. Keep in mind that Bert is one of the most optimized models out there and most of the tools listed above are very mature.
What is interesting is not that Kernl is the fastest engine (or not), but that the code of the kernels is short and easy to understand and modify. We have even added a Triton debugger and a tool (based on Fx) to ease kernel replacement so there is no need to modify PyTorch model source code.
Staying in the comfort of PyTorch / Python maintains dynamic behaviors, debugging and iteration speed. Teams designing/training a transformer model (even custom) can take care of the deployment without relying on advanced GPU knowledge (eg. CUDA programming, dedicated inference engine API, etc.).
Recently released models relying on slightly modified transformer architectures are rarely accelerated in traditional inference engines, we need to wait months to years for someone (usually inference engine maintainers) to write required custom CUDA kernels. Because here custom kernels are written in OpenAI Triton language, anyone without CUDA experience can easily modify them: OpenAI Triton API is simple and close to Numpy one. Kernels source code is significantly shorter than equivalent implementation in CUDA (< 200 LoC per kernel). Basic knowledge of how GPU works is enough. We are also releasing a few tutorials we initially wrote for onboarding colleagues on the project. We hope you will find them useful: https://github.com/ELS-RD/kernl/tree/main/tutorial. In particular, there is:
- Tiled matmul, the GPU way to perform matmul: https://github.com/ELS-RD/kernl/blob/main/tutorial/1%20-%20tiled%20matmul.ipynb
- Simple explanation of what Flash attention is and how it works, a fused attention making long sequences much faster: https://github.com/ELS-RD/kernl/blob/main/tutorial/4%20-%20flash%20attention.ipynb
And best of the best, because we stay in the PyTorch / Python ecosystem, we plan in our roadmap to also enable training with those custom kernels. In particular Flash attention kernel should bring a 2-4X speed up and the support of very long sequences on single GPU (paper authors went as far as 16K tokens instead of traditional 512 or 2048 limits)! See below for more info.
Benchmarking is a difficult art, we tried to be as fair as possible.
Please note that:
- Timings are based on wall-clock times and we show speedup over baseline as they are easier to compare between input shapes,
- When we need to choose between speed and output precision, we always choose precision
- HF baseline, CUDA graphs, Inductor and Kernl are in mixed precision, AITemplate, ONNX Runtime, DeepSpeed and TensorRT have their weights converted to FP16.
- Accumulation is done in FP32 for AITemplate and Kernl. TensorRT is likely doing it in FP16.
- CUDA graphs is enabled for all engines except baseline, Nvfuser and ONNX Runtime which has a limited support of it.
- For Kernl and AITemplate, fast GELU has been manually disabled (TensorRT is likely using Fast GELU).
- AITemplate measures are to be taken with a grain of salt, it doesn’t manage attention mask which means 1/ batch inference can’t be used in most scenarios (no padding support), 2/ it misses few operations on a kernel that can be compute-bounded (depends of sequence length), said otherwise it may make it slower to support attention mask, in particular on long sequences. AITemplate attention mask support will come in a future release.
- For TensorRT for best perf, we built 3 models, one per batch size. AITemplate will support dynamic shapes in a future release, so we made a model per input shape.
- Inductor is in prototype stage, performances may be improved when released, none of the disabled by default optimizations worked during our tests.
As you can see, CUDA graphs erase all CPU overhead (Python related for instance), sometimes there is no need to rely on C++/Rust to be fast! Fused kernels (in CUDA or Triton) are mostly important for longer input sequence lengths. We are aware that there are still some low hanging fruits to improve Kernl performance without sacrificing output precision, it’s just the first release. More info about how it works here.
Why?
We work for Lefebvre Sarrut, a leading European legal publisher. Several of our products include transformer models in latency sensitive scenarios (search, content recommendation). So far, ONNX Runtime and TensorRT served us well, and we learned interesting patterns along the way that we shared with the community through an open-source library called transformer-deploy. However, recent changes in our environment made our needs evolve:
- New teams in the group are deploying transformer models in prod directly with PyTorch. ONNX Runtime poses them too many challenges (like debugging precision issues in fp16). With its inference expert-oriented API, TensorRT was not even an option;
- We are exploring applications of large generative language models in legal industry, and we need easier dynamic behavior support plus more efficient quantization, our creative approaches for that purpose we shared here proved to be more fragile than we initially thought;
- New business opportunities if we were able to train models supporting large contexts (>5K tokens)
On a more personal note, I enjoyed much more writing kernels and understanding low level computation of transformers than mastering multiple complicated tools API and their environments. It really changed my intuitions and understanding about how the model works, scales, etc. It’s not just OpenAI Triton, we also did some prototyping on C++ / CUDA / Cutlass and the effect was the same, it’s all about digging to a lower level. And still the effort is IMO quite limited regarding the benefits. If you have some interest in machine learning engineering, you should probably give those tools a try.
Future?
Our road map includes the following elements (in no particular order):
- Faster warmup
- Ragged inference (no computation lost in padding)
- Training support (with long sequences support)
- Multi GPU (multiple parallelization schemas support)
- Quantization (PTQ)
- New batch of Cutlass kernels tests
- Improve hardware support (>= Ampere for now)
- More tuto
Regarding training, if you want to help, we have written an issue with all the required pointers, it should be very doable: https://github.com/ELS-RD/kernl/issues/93
On top of speed, one of the main benefits is the support of very long sequences (16K tokens without changing attention formula) as it’s based on Flash Attention.
Also, note that future version of PyTorch will include Inductor. It means that all PyTorch users will have the option to compile to Triton to get around 1.7X faster training.
A big thank you to Nvidia people who advised us during this project.